- жµПиІИ: 43969 жђ°
- жАІеИЂ:

- жЭ•иЗ™: е§ІињЮ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2014-09 ( 11)
- 2014-07 ( 2)
- 2014-05 ( 4)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
URLж±Йе≠ЧзЉЦз†БйЧЃйҐШпЉИеПКдє±з†БиІ£еЖ≥пЉЙ
й°µйЭҐдЄ§жђ°иљђз†БпЉЪencodeURI(encodeURI(Ext.get('drug_id').dom.value))
javaйЗМиІ£з†БпЉЪjava.net.URLDecoder.decode(request
.getParameter("drug_id"), "UTF-8")
дЄАгАБйЧЃйҐШзЪДзФ±жЭ•
URLе∞±жШѓзљСеЭАпЉМеП™и¶БдЄКзљСпЉМе∞±дЄАеЃЪдЉЪзФ®еИ∞гАВ

дЄАиИђжЭ•иѓіпЉМURLеП™иГљдљњзФ®иЛ±жЦЗе≠ЧжѓНгАБйШњжЛЙдЉѓжХ∞е≠ЧеТМжЯРдЇЫж†ЗзВєзђ¶еПЈпЉМдЄНиГљдљњзФ®еЕґдїЦжЦЗе≠ЧеТМзђ¶еПЈгАВжѓФе¶ВпЉМдЄЦзХМдЄКжЬЙиЛ±жЦЗе≠ЧжѓНзЪДзљСеЭА вАЬhttp://www.abc.comвАЭпЉМдљЖжШѓж≤°жЬЙеЄМиЕКе≠ЧжѓНзЪДзљСеЭАвАЬhttp://www.aќ≤ќ≥.comвАЭпЉИиѓїдљЬйШње∞Фж≥Х-иіЭе°Ф-дЉљзОЫ.comпЉЙгАВињЩжШѓеЫ†дЄЇзљСзїЬж†ЗеЗЖRFC 1738 еБЪдЇЖз°ђжАІиІДеЃЪпЉЪ
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
вАЬеП™жЬЙе≠ЧжѓНеТМжХ∞е≠Ч[0-9a-zA-Z]гАБдЄАдЇЫзЙєжЃКзђ¶еПЈвАЬ$-_.+!*'(),вАЭ[дЄНеМЕжЛђеПМеЉХеПЈ]гАБдї•еПКжЯРдЇЫдњЭзХЩе≠ЧпЉМжЙНеПѓдї•дЄНзїПињЗзЉЦз†БзЫіжО•зФ®дЇО URLгАВвАЭ
ињЩжДПеС≥зЭАпЉМе¶ВжЮЬURLдЄ≠жЬЙж±Йе≠ЧпЉМе∞±ењЕй°їзЉЦз†БеРОдљњзФ®гАВдљЖжШѓйЇїзГ¶зЪДжШѓпЉМRFC 1738ж≤°жЬЙиІДеЃЪеЕЈдљУзЪДзЉЦз†БжЦєж≥ХпЉМиАМжШѓдЇ§зїЩеЇФзФ®з®ЛеЇПпЉИжµПиІИеЩ®пЉЙиЗ™еЈ±еЖ≥еЃЪгАВињЩеѓЉиЗівАЬURLзЉЦз†БвАЭжИРдЄЇдЇЖдЄАдЄ™жЈЈдє±зЪДйҐЖеЯЯгАВ
дЄЛйЭҐе∞±иЃ©жИСдїђзЬЛзЬЛпЉМвАЬURLзЉЦз†БвАЭеИ∞еЇХжЬЙе§ЪжЈЈдє±гАВжИСдЉЪдЊЭжђ°еИЖжЮРеЫЫзІНдЄНеРМзЪДжГЕеЖµпЉМеЬ®жѓПдЄАзІНжГЕеЖµдЄ≠пЉМжµПиІИеЩ®зЪДURLзЉЦз†БжЦєж≥ХйГљдЄНдЄАж†ЈгАВжККеЃГдїђзЪДеЈЃеЉВиІ£йЗКжЄЕж•ЪдєЛеРОпЉМжИСеЖНиѓіе¶ВдљХзФ®JavascriptжЙЊеИ∞дЄАдЄ™зїЯдЄАзЪДзЉЦз†БжЦєж≥ХгАВ
дЇМгАБжГЕеЖµ1пЉЪзљСеЭАиЈѓеЊДдЄ≠еМЕеРЂж±Йе≠Ч
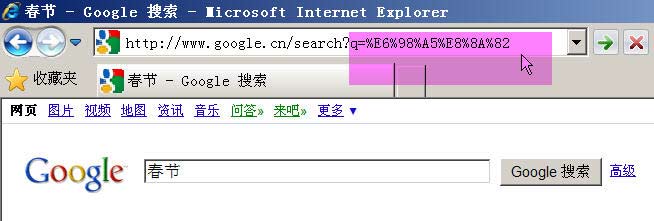
жЙУеЉАIEпЉИжИСзФ®зЪДжШѓ8.0зЙИпЉЙпЉМиЊУеЕ•зљСеЭАвАЬhttp://zh.wikipedia.org/wiki/жШ•иКВ вАЭгАВж≥®жДПпЉМвАЬжШ•иКВвАЭињЩдЄ§дЄ™е≠Чж≠§жЧґжШѓзљСеЭАиЈѓеЊДзЪДдЄАйГ®еИЖгАВ

жЯ•зЬЛHTTPиѓЈж±ВзЪДе§ідњ°жБѓпЉМдЉЪеПСзО∞IEеЃЮйЩЕжߕ胥зЪДзљСеЭАжШѓвАЬhttp://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82 вАЭгАВдєЯе∞±жШѓиѓіпЉМIEиЗ™еК®е∞ЖвАЬжШ•иКВвАЭзЉЦз†БжИРдЇЖвАЬ%E6%98%A5%E8%8A%82вАЭгАВ
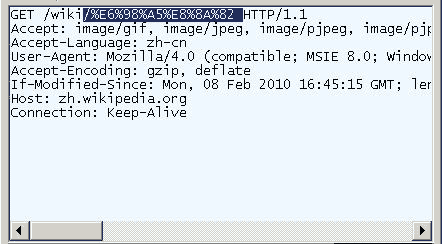
жИСдїђзЯ•йБУпЉМвАЬжШ•вАЭеТМвАЬиКВвАЭзЪДutf-8зЉЦз†БеИЖеИЂжШѓвАЬE6 98 A5вАЭеТМвАЬE8 8A 82вАЭпЉМеЫ†ж≠§пЉМвАЬ%E6%98%A5%E8%8A%82вАЭе∞±жШѓжМЙзЕІй°ЇеЇПпЉМеЬ®жѓПдЄ™е≠ЧиКВеЙНеК†дЄК%иАМеЊЧеИ∞зЪДгАВпЉИеЕЈдљУзЪДиљђз†БжЦєж≥ХпЉМиѓЈеПВиАГжИСеЖЩзЪДгАКе≠Чзђ¶зЉЦз†БзђФиЃ∞гАЛ гАВпЉЙ
еЬ®FirefoxдЄ≠жµЛиѓХпЉМдєЯеЊЧеИ∞дЇЖеРМж†ЈзЪДзїУжЮЬгАВжЙАдї•пЉМзїУиЃЇ1е∞±жШѓпЉМзљСеЭАиЈѓеЊДзЪДзЉЦз†БпЉМзФ®зЪДжШѓutf-8зЉЦз†БгАВ
дЄЙгАБжГЕеЖµ2пЉЪжߕ胥е≠Чзђ¶дЄ≤еМЕеРЂж±Йе≠Ч
еЬ®IEдЄ≠иЊУеЕ•зљСеЭАвАЬhttp://www.baidu.com/s?wd=жШ•иКВ вАЭгАВж≥®жДПпЉМвАЬжШ•иКВвАЭињЩдЄ§дЄ™е≠Чж≠§жЧґе±ЮдЇОжߕ胥е≠Чзђ¶дЄ≤пЉМдЄНе±ЮдЇОзљСеЭАиЈѓеЊДпЉМдЄНи¶БдЄОжГЕеЖµ1жЈЈжЈЖгАВ

жЯ•зЬЛHTTPиѓЈж±ВзЪДе§ідњ°жБѓпЉМдЉЪеПСзО∞IEе∞ЖвАЬжШ•иКВвАЭиљђеМЦжИРдЇЖдЄАдЄ™дє±з†БгАВ
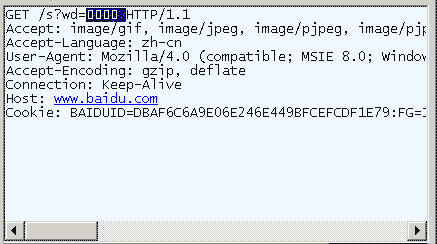
еИЗжНҐеИ∞еНБеЕ≠ињЫеИґжЦєеЉПпЉМжЙНиГљжЄЕж•ЪеЬ∞зЬЛеИ∞пЉМвАЬжШ•иКВвАЭ襀蚐жИРдЇЖвАЬB4 BA BD DAвАЭгАВ
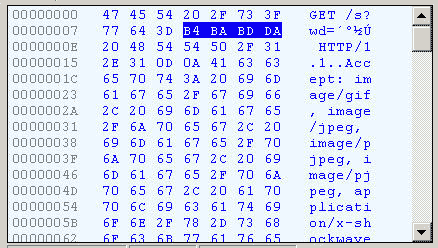
жИСдїђзЯ•йБУпЉМвАЬжШ•вАЭеТМвАЬиКВвАЭзЪДGB2312зЉЦз†БпЉИжИСзЪДжУНдљЬз≥їзїЯвАЬWindows XPвАЭдЄ≠жЦЗзЙИзЪДйїШиЃ§зЉЦз†БпЉЙеИЖеИЂжШѓвАЬB4 BAвАЭеТМвАЬBD DAвАЭгАВеЫ†ж≠§пЉМIEеЃЮйЩЕдЄКе∞±жШѓе∞Жжߕ胥е≠Чзђ¶дЄ≤пЉМдї•GB2312зЉЦз†БзЪДж†ЉеЉПеПСйАБеЗЇеОїгАВ
FirefoxзЪДе§ДзРЖжЦєж≥ХпЉМзХ•жЬЙдЄНеРМгАВеЃГеПСйАБзЪДHTTP HeadжШѓвАЬwd=%B4%BA%BD%DAвАЭгАВдєЯе∞±жШѓиѓіпЉМеРМж†ЈйЗЗзФ®GB2312зЉЦз†БпЉМдљЖжШѓеЬ®жѓПдЄ™е≠ЧиКВеЙНеК†дЄКдЇЖ%гАВ
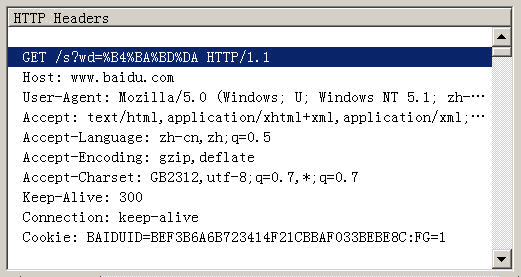
жЙАдї•пЉМзїУиЃЇ2е∞±жШѓпЉМжߕ胥е≠Чзђ¶дЄ≤зЪДзЉЦз†БпЉМзФ®зЪДжШѓжУНдљЬз≥їзїЯзЪДйїШиЃ§зЉЦз†БгАВ
еЫЫгАБжГЕеЖµ3пЉЪGetжЦєж≥ХзФЯжИРзЪДURLеМЕеРЂж±Йе≠Ч
еЙНйЭҐиѓізЪДжШѓзЫіжО•иЊУеЕ•зљСеЭАзЪДжГЕеЖµпЉМдљЖжШѓжЫіеЄЄиІБзЪДжГЕеЖµжШѓпЉМеЬ®еЈ≤жЙУеЉАзЪДзљСй°µдЄКпЉМзЫіжО•зФ®GetжИЦPostжЦєж≥ХеПСеЗЇHTTPиѓЈж±ВгАВ
ж†єжНЃеП∞жєЊдЄ≠еЕіе§Іе≠¶еРХзСЮйЇЯиАБеЄИзЪДиѓХй™М пЉМињЩжЧґзЪДзЉЦз†БжЦєж≥ХзФ±зљСй°µзЪДзЉЦз†БеЖ≥еЃЪпЉМдєЯе∞±жШѓзФ±HTMLжЇРз†БдЄ≠е≠Чзђ¶йЫЖзЪДиЃЊеЃЪеЖ≥еЃЪгАВ
гААгАА<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
е¶ВжЮЬдЄКйЭҐињЩдЄАи°МжЬАеРОзЪДcharsetжШѓUTF-8пЉМеИЩURLе∞±дї•UTF-8зЉЦз†БпЉЫе¶ВжЮЬжШѓGB2312пЉМURLе∞±дї•GB2312зЉЦз†БгАВ
дЄЊдЊЛжЭ•иѓіпЉМзЩЊеЇ¶жШѓGB2312зЉЦз†БпЉМGoogleжШѓUTF-8зЉЦз†БгАВеЫ†ж≠§пЉМдїОеЃГдїђзЪДжРЬ糥ж°ЖдЄ≠жРЬ糥еРМдЄАдЄ™иѓНвАЬжШ•иКВвАЭпЉМзФЯжИРзЪДжߕ胥е≠Чзђ¶дЄ≤жШѓдЄНдЄАж†ЈзЪДгАВ
зЩЊеЇ¶зФЯжИРзЪДжШѓ%B4%BA%BD%DAпЉМињЩжШѓGB2312зЉЦз†БгАВ
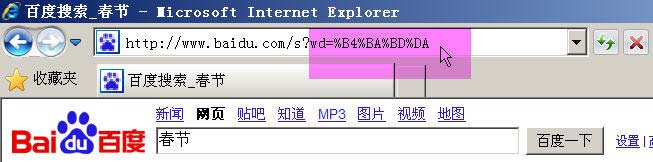
GoogleзФЯжИРзЪДжШѓ%E6%98%A5%E8%8A%82пЉМињЩжШѓUTF-8зЉЦз†БгАВ
жЙАдї•пЉМзїУиЃЇ3е∞±жШѓпЉМGETеТМPOSTжЦєж≥ХзЪДзЉЦз†БпЉМзФ®зЪДжШѓзљСй°µзЪДзЉЦз†БгАВ
дЇФгАБжГЕеЖµ4пЉЪAjaxи∞ГзФ®зЪДURLеМЕеРЂж±Йе≠Ч
еЙНйЭҐдЄЙзІНжГЕеЖµйГљжШѓзФ±жµПиІИеЩ®еПСеЗЇHTTPиѓЈж±ВпЉМжЬАеРОдЄАзІНжГЕеЖµеИЩжШѓзФ±JavascriptзФЯжИРHTTPиѓЈж±ВпЉМдєЯе∞±жШѓAjaxи∞ГзФ®гАВињШжШѓж†єжНЃеРХзСЮйЇЯиАБеЄИзЪДжЦЗзЂ†пЉМеЬ®ињЩзІНжГЕеЖµдЄЛпЉМIEеТМFirefoxзЪДе§ДзРЖжЦєеЉПеЃМеЕ®дЄНдЄАж†ЈгАВ
дЄЊдЊЛжЭ•иѓіпЉМжЬЙињЩж†ЈдЄ§и°Мдї£з†БпЉЪ
гААгААurl = url + "?q=" +document.myform.elements[0].value; // еБЗеЃЪзФ®жИЈеЬ®и°®еНХдЄ≠жПРдЇ§зЪДеАЉжШѓвАЬжШ•иКВвАЭињЩдЄ§дЄ™е≠Ч
гААгААhttp_request.open('GET', url, true);
йВ£дєИпЉМжЧ†иЃЇзљСй°µдљњзФ®дїАдєИе≠Чзђ¶йЫЖпЉМIEдЉ†йАБзїЩжЬНеК°еЩ®зЪДжАїжШѓвАЬq=%B4%BA%BD%DAвАЭпЉМиАМFirefoxдЉ†йАБзїЩжЬНеК°еЩ®зЪДжАїжШѓвАЬq=%E6%98 %A5%E8%8A%82вАЭгАВдєЯе∞±жШѓиѓіпЉМеЬ®Ajaxи∞ГзФ®дЄ≠пЉМIEжАїжШѓйЗЗзФ®GB2312зЉЦз†БпЉИжУНдљЬз≥їзїЯзЪДйїШиЃ§зЉЦз†БпЉЙпЉМиАМFirefoxжАїжШѓйЗЗзФ®utf-8зЉЦз†БгАВињЩе∞±жШѓжИСдїђзЪДзїУиЃЇ4гАВ
еЕ≠гАБJavascriptеЗљжХ∞пЉЪescape()
е•љдЇЖпЉМеИ∞ж≠§дЄЇж≠ҐпЉМеЫЫзІНжГЕеЖµйГљиѓіеЃМдЇЖгАВ
еБЗеЃЪеЙНйЭҐдљ†йГљзЬЛжЗВдЇЖпЉМйВ£дєИж≠§жЧґдљ†еЇФиѓ•дЉЪжДЯеИ∞еЊИе§ізЧЫгАВеЫ†дЄЇпЉМеЃЮеܮ姙棣亱дЇЖгАВдЄНеРМзЪДжУНдљЬз≥їзїЯгАБдЄНеРМзЪДжµПиІИеЩ®гАБдЄНеРМзЪДзљСй°µе≠Чзђ¶йЫЖпЉМе∞ЖеѓЉиЗіеЃМеЕ®дЄНеРМзЪДзЉЦз†БзїУжЮЬгАВе¶ВжЮЬз®ЛеЇПеСШи¶БжККжѓПдЄАзІНзїУжЮЬйГљиАГиЩСињЫеОїпЉМжШѓдЄНж؃姙жБРжАЦдЇЖпЉЯжЬЙж≤°жЬЙеКЮж≥ХпЉМиГље§ЯдњЭиѓБеЃҐжИЈзЂѓеП™зФ®дЄАзІНзЉЦз†БжЦєж≥ХеРСжЬНеК°еЩ®еПСеЗЇиѓЈж±ВпЉЯ
еЫЮз≠ФжШѓжЬЙзЪДпЉМе∞±жШѓдљњзФ®JavascriptеЕИеѓєURLзЉЦз†БпЉМзДґеРОеЖНеРСжЬНеК°еЩ®жПРдЇ§пЉМдЄНи¶БзїЩжµПиІИеЩ®жПТжЙЛзЪДжЬЇдЉЪгАВеЫ†дЄЇJavascriptзЪДиЊУеЗЇжАїжШѓдЄАиЗізЪДпЉМжЙАдї•е∞±дњЭиѓБдЇЖжЬНеК°еЩ®еЊЧеИ∞зЪДжХ∞жНЃжШѓж†ЉеЉПзїЯдЄАзЪДгАВ
Javascriptиѓ≠и®АзФ®дЇОзЉЦз†БзЪДеЗљжХ∞пЉМдЄАеЕ±жЬЙдЄЙдЄ™пЉМжЬАеП§иАБзЪДдЄАдЄ™е∞±жШѓescape()гАВиЩљзДґињЩдЄ™еЗљжХ∞зО∞еЬ®еЈ≤зїПдЄНжПРеА°дљњзФ®дЇЖпЉМдљЖжШѓзФ±дЇОеОЖеП≤еОЯеЫ†пЉМеЊИе§ЪеЬ∞жЦєињШеЬ®дљњзФ®еЃГпЉМжЙАдї•жЬЙењЕи¶БеЕИдїОеЃГиЃ≤иµЈгАВ
еЃЮйЩЕдЄКпЉМescape()дЄНиГљзЫіжО•зФ®дЇОURLзЉЦз†БпЉМеЃГзЪДзЬЯж≠£дљЬзФ®жШѓињФеЫЮдЄАдЄ™е≠Чзђ¶зЪДUnicodeзЉЦз†БеАЉгАВжѓФе¶ВвАЬжШ•иКВвАЭзЪДињФеЫЮзїУжЮЬжШѓ%u6625%u8282пЉМдєЯе∞±жШѓиѓіеЬ®Unicodeе≠Чзђ¶йЫЖдЄ≠пЉМвАЬжШ•вАЭжШѓзђђ6625дЄ™пЉИеНБеЕ≠ињЫеИґпЉЙе≠Чзђ¶пЉМвАЬиКВвАЭжШѓзђђ8282дЄ™пЉИеНБеЕ≠ињЫеИґпЉЙе≠Чзђ¶гАВ

еЃГзЪДеЕЈдљУиІДеИЩжШѓпЉМйЩ§дЇЖASCIIе≠ЧжѓНгАБжХ∞е≠ЧгАБж†ЗзВєзђ¶еПЈвАЬ@ * _ + - . /вАЭдї•е§ЦпЉМеѓєеЕґдїЦжЙАжЬЙе≠Чзђ¶ињЫи°МзЉЦз†БгАВеЬ®\u0000еИ∞\u00ffдєЛйЧізЪДзђ¶еϣ襀蚐жИР%xxзЪД嚥еЉПпЉМеЕґдљЩзђ¶еϣ襀蚐жИР%uxxxxзЪД嚥еЉПгАВеѓєеЇФзЪДиІ£з†БеЗљжХ∞жШѓ unescape()гАВ
жЙАдї•пЉМвАЬHello WorldвАЭзЪДescape()зЉЦз†Бе∞±жШѓвАЬHello%20WorldвАЭгАВеЫ†дЄЇз©Їж†ЉзЪДUnicodeеАЉжШѓ20пЉИеНБеЕ≠ињЫеИґпЉЙгАВ

ињШжЬЙдЄ§дЄ™еЬ∞жЦєйЬАи¶Бж≥®жДПгАВ
й¶ЦеЕИпЉМжЧ†иЃЇзљСй°µзЪДеОЯеІЛзЉЦз†БжШѓдїАдєИпЉМдЄАж׶襀JavascriptзЉЦз†БпЉМе∞±йГљеПШдЄЇunicodeе≠Чзђ¶гАВдєЯе∞±жШѓиѓіпЉМJavasciptеЗљжХ∞зЪДиЊУеЕ•еТМиЊУеЗЇпЉМйїШиЃ§йГљжШѓUnicodeе≠Чзђ¶гАВињЩдЄАзВєеѓєдЄЛйЭҐдЄ§дЄ™еЗљжХ∞дєЯйАВзФ®гАВ

еЕґжђ°пЉМescape()дЄНеѓєвАЬ+вАЭзЉЦз†БгАВдљЖжШѓжИСдїђзЯ•йБУпЉМзљСй°µеЬ®жПРдЇ§и°®еНХзЪДжЧґеАЩпЉМе¶ВжЮЬжЬЙз©Їж†ЉпЉМеИЩдЉЪ襀蚐еМЦдЄЇ+е≠Чзђ¶гАВжЬНеК°еЩ®е§ДзРЖжХ∞жНЃзЪДжЧґеАЩпЉМдЉЪжКК+еПЈе§ДзРЖжИРз©Їж†ЉгАВжЙАдї•пЉМдљњзФ®зЪДжЧґеАЩи¶Бе∞ПењГгАВ
дЄГгАБJavascriptеЗљжХ∞пЉЪencodeURI()
encodeURI()жШѓJavascriptдЄ≠зЬЯж≠£зФ®жЭ•еѓєURLзЉЦз†БзЪДеЗљжХ∞гАВ
еЃГзЭАзЬЉдЇОеѓєжХідЄ™URLињЫи°МзЉЦз†БпЉМеЫ†ж≠§йЩ§дЇЖеЄЄиІБзЪДзђ¶еПЈдї•е§ЦпЉМеѓєеЕґдїЦдЄАдЇЫеЬ®зљСеЭАдЄ≠жЬЙзЙєжЃКеРЂдєЙзЪДзђ¶еПЈвАЬ; / ? : @ & = + $ , #вАЭпЉМдєЯдЄНињЫи°МзЉЦз†БгАВзЉЦз†БеРОпЉМеЃГиЊУеЗЇзђ¶еПЈзЪДutf-8嚥еЉПпЉМеєґдЄФеЬ®жѓПдЄ™е≠ЧиКВеЙНеК†дЄК%гАВ
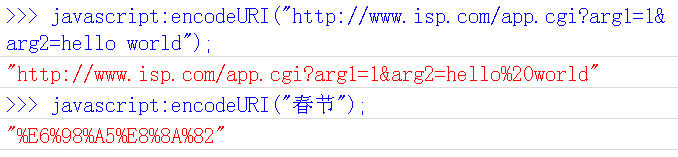
еЃГеѓєеЇФзЪДиІ£з†БеЗљжХ∞жШѓdecodeURI()гАВ

йЬАи¶Бж≥®жДПзЪДжШѓпЉМеЃГдЄНеѓєеНХеЉХеПЈ'зЉЦз†БгАВ
еЕЂгАБJavascriptеЗљжХ∞пЉЪencodeURIComponent()
жЬАеРОдЄАдЄ™JavascriptзЉЦз†БеЗљжХ∞жШѓencodeURIComponent()гАВдЄОencodeURI()зЪДеМЇеИЂжШѓпЉМеЃГзФ®дЇОеѓєURLзЪДзїДжИРйГ®еИЖињЫи°МдЄ™еИЂзЉЦз†БпЉМиАМдЄНзФ®дЇОеѓєжХідЄ™URLињЫи°МзЉЦз†БгАВ
еЫ†ж≠§пЉМвАЬ; / ? : @ & = + $ , #вАЭпЉМињЩдЇЫеЬ®encodeURI()дЄ≠дЄН襀зЉЦз†БзЪДзђ¶еПЈпЉМеЬ®encodeURIComponent()дЄ≠зїЯзїЯдЉЪ襀зЉЦз†БгАВиЗ≥дЇОеЕЈдљУзЪДзЉЦз†БжЦєж≥ХпЉМдЄ§иАЕжШѓдЄАж†ЈгАВ
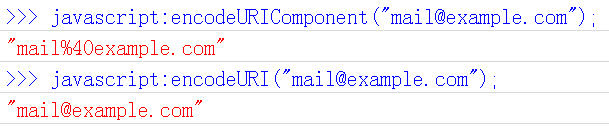
еЃГеѓєеЇФзЪДиІ£з†БеЗљжХ∞жШѓdecodeURIComponent()гАВ
PS1 пЉЪ
зљСй°µйЗМзЪДformзЉЦз†БеЕґеЃЮдЄНеЃМеЕ®еПЦеЖ≥дЇОзљСй°µзЉЦз†БпЉМformж†ЗиЃ∞дЄ≠жЬЙдЄАдЄ™accept-charsetе±ЮжАІпЉМеЬ®йЭЮieжµПиІИеЩ®зІНпЉМе¶ВжЮЬе∞ЖеЕґиµЛеАЉ(жѓФе¶В accept-charset="UTF-8")пЉМеИЩи°®еНХдЉЪжМЙзЕІињЩдЄ™еАЉи°®з§ЇзЪДзЉЦз†БжЦєеЉПињЫи°МжПРдЇ§гАВ
еЬ®ieдЄЛпЉМжИСзЪДеЕЉеЃєиІ£еЖ≥еКЮж≥ХжШѓпЉЪ
form1.onsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
PS2 пЉЪе≠Чзђ¶зЉЦз†БзђФиЃ∞пЉЪASCIIпЉМUnicodeеТМ UTF-8
1. ASCIIз†Б
жИСдїђзЯ•йБУпЉМеЬ®иЃ°зЃЧжЬЇеЖЕйГ®пЉМжЙАжЬЙзЪДдњ°жБѓжЬАзїИйГљи°®з§ЇдЄЇдЄАдЄ™дЇМињЫеИґзЪДе≠Чзђ¶дЄ≤гАВжѓПдЄАдЄ™дЇМињЫеИґдљНпЉИbitпЉЙжЬЙ0еТМ1дЄ§зІНзКґжАБпЉМеЫ†ж≠§еЕЂдЄ™дЇМињЫеИґдљНе∞±еПѓдї•зїДеРИеЗЇ 256зІНзКґжАБпЉМињЩ襀зІ∞дЄЇдЄАдЄ™е≠ЧиКВпЉИbyteпЉЙгАВдєЯе∞±жШѓиѓіпЉМдЄАдЄ™е≠ЧиКВдЄАеЕ±еПѓдї•зФ®жЭ•и°®з§Ї256зІНдЄНеРМзЪДзКґжАБпЉМжѓПдЄАдЄ™зКґжАБеѓєеЇФдЄАдЄ™зђ¶еПЈпЉМе∞±жШѓ256дЄ™зђ¶еПЈпЉМдїО 0000000еИ∞11111111гАВ
дЄКдЄ™дЄЦзЇ™60еєідї£пЉМзЊОеЫљеИґеЃЪдЇЖдЄАе•Че≠Чзђ¶зЉЦз†БпЉМеѓєиЛ±иѓ≠е≠Чзђ¶дЄОдЇМињЫеИґдљНдєЛйЧізЪДеЕ≥з≥їпЉМеБЪдЇЖзїЯдЄАиІДеЃЪгАВињЩ襀зІ∞дЄЇASCIIз†БпЉМдЄАзЫіж≤њзФ®иЗ≥дїКгАВ
ASCIIз†БдЄАеЕ±иІДеЃЪдЇЖ128дЄ™е≠Чзђ¶зЪДзЉЦз†БпЉМжѓФе¶Вз©Їж†ЉвАЬSPACEвАЭжШѓ32пЉИдЇМињЫеИґ00100000пЉЙпЉМе§ІеЖЩзЪДе≠ЧжѓНAжШѓ65пЉИдЇМињЫеИґ 01000001пЉЙгАВињЩ128дЄ™зђ¶еПЈпЉИеМЕжЛђ32дЄ™дЄНиГљжЙУеН∞еЗЇжЭ•зЪДжОІеИґзђ¶еПЈпЉЙпЉМеП™еН†зФ®дЇЖдЄАдЄ™е≠ЧиКВзЪДеРОйЭҐ7дљНпЉМжЬАеЙНйЭҐзЪД1дљНзїЯдЄАиІДеЃЪдЄЇ0гАВ
2гАБйЭЮASCIIзЉЦз†Б
иЛ±иѓ≠зФ®128дЄ™зђ¶еПЈзЉЦз†Бе∞±е§ЯдЇЖпЉМдљЖжШѓзФ®жЭ•и°®з§ЇеЕґдїЦиѓ≠и®АпЉМ128дЄ™зђ¶еПЈжШѓдЄНе§ЯзЪДгАВжѓФе¶ВпЉМеЬ®ж≥Хиѓ≠дЄ≠пЉМе≠ЧжѓНдЄКжЦєжЬЙж≥®йЯ≥зђ¶еПЈпЉМеЃГе∞±жЧ†ж≥ХзФ®ASCIIз†Би°®з§ЇгАВдЇОжШѓпЉМдЄАдЇЫжђІжі≤еЫљеЃґе∞±еЖ≥еЃЪпЉМеИ©зФ®е≠ЧиКВдЄ≠йЧ≤зљЃзЪДжЬАйЂШдљНзЉЦеЕ•жЦ∞зЪДзђ¶еПЈгАВжѓФе¶ВпЉМж≥Хиѓ≠дЄ≠зЪД√©зЪДзЉЦз†БдЄЇ130пЉИдЇМињЫеИґ10000010пЉЙгАВињЩж†ЈдЄАжЭ•пЉМињЩдЇЫжђІжі≤еЫљеЃґдљњзФ®зЪДзЉЦз†БдљУз≥їпЉМеПѓдї•и°®з§ЇжЬАе§Ъ256дЄ™зђ¶еПЈгАВ
дљЖжШѓпЉМињЩйЗМеПИеЗЇзО∞дЇЖжЦ∞зЪДйЧЃйҐШгАВдЄНеРМзЪДеЫљеЃґжЬЙдЄНеРМзЪДе≠ЧжѓНпЉМеЫ†ж≠§пЉМеУ™жАХеЃГдїђйГљдљњзФ®256дЄ™зђ¶еПЈзЪДзЉЦз†БжЦєеЉПпЉМдї£и°®зЪДе≠ЧжѓНеНідЄНдЄАж†ЈгАВжѓФе¶ВпЉМ130еЬ®ж≥Хиѓ≠зЉЦз†БдЄ≠дї£и°®дЇЖ√©пЉМеЬ®еЄМдЉѓжЭ•иѓ≠зЉЦз†БдЄ≠еНідї£и°®дЇЖе≠ЧжѓНGimel („Т)пЉМеЬ®дњДиѓ≠зЉЦз†БдЄ≠еПИдЉЪдї£и°®еП¶дЄАдЄ™зђ¶еПЈгАВдљЖжШѓдЄНзЃ°жАОж†ЈпЉМжЙАжЬЙињЩдЇЫзЉЦз†БжЦєеЉПдЄ≠пЉМ0вАФ127и°®з§ЇзЪДзђ¶еПЈжШѓдЄАж†ЈзЪДпЉМдЄНдЄАж†ЈзЪДеП™жШѓ128вАФ255зЪДињЩдЄАжЃµгАВ
иЗ≥дЇОдЇЪжі≤еЫљеЃґзЪДжЦЗе≠ЧпЉМдљњзФ®зЪДзђ¶еПЈе∞±жЫіе§ЪдЇЖпЉМж±Йе≠Че∞±е§ЪиЊЊ10дЄЗеЈ¶еП≥гАВдЄАдЄ™е≠ЧиКВеП™иГљи°®з§Ї256зІНзђ¶еПЈпЉМиВѓеЃЪжШѓдЄНе§ЯзЪДпЉМе∞±ењЕй°їдљњзФ®е§ЪдЄ™е≠ЧиКВи°®иЊЊдЄАдЄ™зђ¶еПЈгАВжѓФе¶ВпЉМзЃАдљУдЄ≠жЦЗеЄЄиІБзЪДзЉЦз†БжЦєеЉПжШѓGB2312пЉМдљњзФ®дЄ§дЄ™е≠ЧиКВи°®з§ЇдЄАдЄ™ж±Йе≠ЧпЉМжЙАдї•зРЖиЃЇдЄКжЬАе§ЪеПѓдї•и°®з§Ї256x256=65536дЄ™зђ¶еПЈгАВ
дЄ≠жЦЗзЉЦз†БзЪДйЧЃйҐШйЬАи¶БдЄУжЦЗиЃ®иЃЇпЉМињЩзѓЗзђФиЃ∞дЄНжґЙеПКгАВињЩйЗМеП™жМЗеЗЇпЉМиЩљзДґйГљжШѓзФ®е§ЪдЄ™е≠ЧиКВи°®з§ЇдЄАдЄ™зђ¶еПЈпЉМдљЖжШѓGBз±їзЪДж±Йе≠ЧзЉЦз†БдЄОеРОжЦЗзЪДUnicodeеТМ UTF-8жШѓжѓЂжЧ†еЕ≥з≥їзЪДгАВ
3.Unicode
ж≠£е¶ВдЄКдЄАиКВжЙАиѓіпЉМдЄЦзХМдЄКе≠ШеЬ®зЭАе§ЪзІНзЉЦз†БжЦєеЉПпЉМеРМдЄАдЄ™дЇМињЫеИґжХ∞е≠ЧеПѓдї•иҐЂиІ£йЗКжИРдЄНеРМзЪДзђ¶еПЈгАВеЫ†ж≠§пЉМи¶БжГ≥жЙУеЉАдЄАдЄ™жЦЗжЬђжЦЗдїґпЉМе∞±ењЕй°їзЯ•йБУеЃГзЪДзЉЦз†БжЦєеЉПпЉМеР¶еИЩзФ®йФЩиѓѓзЪДзЉЦз†БжЦєеЉПиІ£иѓїпЉМе∞±дЉЪеЗЇзО∞дє±з†БгАВдЄЇдїАдєИзФµе≠РйВЃдїґеЄЄеЄЄеЗЇзО∞дє±з†БпЉЯе∞±жШѓеЫ†дЄЇеПСдњ°дЇЇеТМжФґдњ°дЇЇдљњзФ®зЪДзЉЦз†БжЦєеЉПдЄНдЄАж†ЈгАВ
еПѓдї•жГ≥и±°пЉМе¶ВжЮЬжЬЙдЄАзІНзЉЦз†БпЉМе∞ЖдЄЦзХМдЄКжЙАжЬЙзЪДзђ¶еПЈйГљзЇ≥еЕ•еЕґдЄ≠гАВжѓПдЄАдЄ™зђ¶еПЈйГљзїЩдЇИдЄАдЄ™зЛђдЄАжЧ†дЇМзЪДзЉЦз†БпЉМйВ£дєИдє±з†БйЧЃйҐШе∞±дЉЪжґИ姱гАВињЩе∞±жШѓUnicodeпЉМе∞±еГПеЃГзЪДеРНе≠ЧйГљи°®з§ЇзЪДпЉМињЩжШѓдЄАзІНжЙАжЬЙзђ¶еПЈзЪДзЉЦз†БгАВ
UnicodeељУзДґжШѓдЄАдЄ™еЊИе§ІзЪДйЫЖеРИпЉМзО∞еЬ®зЪДиІДж®°еПѓдї•еЃєзЇ≥100е§ЪдЄЗдЄ™зђ¶еПЈгАВжѓПдЄ™зђ¶еПЈзЪДзЉЦз†БйГљдЄНдЄАж†ЈпЉМжѓФе¶ВпЉМU+0639и°®з§ЇйШњжЛЙдЉѓе≠ЧжѓН AinпЉМU+0041и°®з§ЇиЛ±иѓ≠зЪДе§ІеЖЩе≠ЧжѓНAпЉМU+4E25и°®з§Їж±Йе≠ЧвАЬдЄ•вАЭгАВеЕЈдљУзЪДзђ¶еПЈеѓєеЇФи°®пЉМеПѓдї•жߕ胥unicode.org пЉМжИЦиАЕдЄУйЧ®зЪДж±Йе≠ЧеѓєеЇФи°® гАВ
4. UnicodeзЪДйЧЃйҐШ
йЬАи¶Бж≥®жДПзЪДжШѓпЉМUnicodeеП™жШѓдЄАдЄ™зђ¶еПЈйЫЖпЉМеЃГеП™иІДеЃЪдЇЖзђ¶еПЈзЪДдЇМињЫеИґдї£з†БпЉМеНіж≤°жЬЙиІДеЃЪињЩдЄ™дЇМињЫеИґдї£з†БеЇФиѓ•е¶ВдљХе≠ШеВ®гАВ
жѓФе¶ВпЉМж±Йе≠ЧвАЬдЄ•вАЭзЪДunicodeжШѓеНБеЕ≠ињЫеИґжХ∞4E25пЉМиљђжНҐжИРдЇМињЫеИґжХ∞иґ≥иґ≥жЬЙ15дљНпЉИ100111000100101пЉЙпЉМдєЯе∞±жШѓиѓіињЩдЄ™зђ¶еПЈзЪДи°®з§ЇиЗ≥е∞СйЬАи¶Б2дЄ™е≠ЧиКВгАВи°®з§ЇеЕґдїЦжЫіе§ІзЪДзђ¶еПЈпЉМеПѓиГљйЬАи¶Б3дЄ™е≠ЧиКВжИЦиАЕ4дЄ™е≠ЧиКВпЉМзФЪиЗ≥жЫіе§ЪгАВ
ињЩйЗМе∞±жЬЙдЄ§дЄ™дЄ•йЗНзЪДйЧЃйҐШпЉМзђђдЄАдЄ™йЧЃйҐШжШѓпЉМе¶ВдљХжЙНиГљеМЇеИЂunicodeеТМasciiпЉЯиЃ°зЃЧжЬЇжАОдєИзЯ•йБУдЄЙдЄ™е≠ЧиКВи°®з§ЇдЄАдЄ™зђ¶еПЈпЉМиАМдЄНжШѓеИЖеИЂи°®з§ЇдЄЙдЄ™зђ¶еПЈеСҐпЉЯзђђдЇМдЄ™йЧЃйҐШжШѓпЉМжИСдїђеЈ≤зїПзЯ•йБУпЉМиЛ±жЦЗе≠ЧжѓНеП™зФ®дЄАдЄ™е≠ЧиКВи°®з§Їе∞±е§ЯдЇЖпЉМе¶ВжЮЬunicodeзїЯдЄАиІДеЃЪпЉМжѓПдЄ™зђ¶еПЈзФ®дЄЙдЄ™жИЦеЫЫдЄ™е≠ЧиКВи°®з§ЇпЉМйВ£дєИжѓПдЄ™иЛ±жЦЗе≠ЧжѓНеЙНйГљењЕзДґжЬЙдЇМеИ∞дЄЙдЄ™е≠ЧиКВжШѓ0пЉМињЩеѓєдЇОе≠ШеВ®жЭ•иѓіжШѓжЮБе§ІзЪДжµ™иієпЉМжЦЗжЬђжЦЗдїґзЪДе§Іе∞ПдЉЪеЫ†ж≠§е§ІеЗЇдЇМдЄЙеАНпЉМињЩжШѓжЧ†ж≥ХжО•еПЧзЪДгАВ
еЃГдїђйА†жИРзЪДзїУжЮЬжШѓпЉЪ1пЉЙеЗЇзО∞дЇЖunicodeзЪДе§ЪзІНе≠ШеВ®жЦєеЉПпЉМдєЯе∞±жШѓиѓіжЬЙиЃЄе§ЪзІНдЄНеРМзЪДдЇМињЫеИґж†ЉеЉПпЉМеПѓдї•зФ®жЭ•и°®з§ЇunicodeгАВ2пЉЙunicode еЬ®еЊИйХњдЄАжЃµжЧґйЧіеЖЕжЧ†ж≥ХжО®еєњпЉМзЫіеИ∞дЇТиБФзљСзЪДеЗЇзО∞гАВ
5.UTF-8
дЇТиБФзљСзЪДжЩЃеПКпЉМеЉЇзГИи¶Бж±ВеЗЇзО∞дЄАзІНзїЯдЄАзЪДзЉЦз†БжЦєеЉПгАВUTF-8е∞±жШѓеЬ®дЇТиБФзљСдЄКдљњзФ®жЬАеєњзЪДдЄАзІНunicodeзЪДеЃЮзО∞жЦєеЉПгАВеЕґдїЦеЃЮзО∞жЦєеЉПињШеМЕжЛђUTF- 16еТМUTF-32пЉМдЄНињЗеЬ®дЇТиБФзљСдЄКеЯЇжЬђдЄНзФ®гАВйЗНе§НдЄАйБНпЉМињЩйЗМзЪДеЕ≥з≥їжШѓпЉМUTF-8жШѓUnicodeзЪДеЃЮзО∞жЦєеЉПдєЛдЄАгАВ
UTF-8жЬАе§ІзЪДдЄАдЄ™зЙєзВєпЉМе∞±жШѓеЃГжШѓдЄАзІНеПШйХњзЪДзЉЦз†БжЦєеЉПгАВеЃГеПѓдї•дљњзФ®1~4дЄ™е≠ЧиКВи°®з§ЇдЄАдЄ™зђ¶еПЈпЉМж†єжНЃдЄНеРМзЪДзђ¶еПЈиАМеПШеМЦе≠ЧиКВйХњеЇ¶гАВ
UTF-8зЪДзЉЦз†БиІДеИЩеЊИзЃАеНХпЉМеП™жЬЙдЇМжЭ°пЉЪ
1пЉЙеѓєдЇОеНХе≠ЧиКВзЪДзђ¶еПЈпЉМе≠ЧиКВзЪДзђђдЄАдљНиЃЊдЄЇ0пЉМеРОйЭҐ7дљНдЄЇињЩдЄ™зђ¶еПЈзЪДunicodeз†БгАВеЫ†ж≠§еѓєдЇОиЛ±иѓ≠е≠ЧжѓНпЉМUTF-8зЉЦз†БеТМASCIIз†БжШѓзЫЄеРМзЪДгАВ
2пЉЙеѓєдЇОnе≠ЧиКВзЪДзђ¶еПЈпЉИn>1пЉЙпЉМзђђдЄАдЄ™е≠ЧиКВзЪДеЙНnдљНйГљиЃЊдЄЇ1пЉМзђђn+1дљНиЃЊдЄЇ0пЉМеРОйЭҐе≠ЧиКВзЪДеЙНдЄ§дљНдЄАеЊЛиЃЊдЄЇ10гАВеЙ©дЄЛзЪДж≤°жЬЙжПРеПКзЪДдЇМињЫеИґдљНпЉМеЕ®йГ®дЄЇињЩдЄ™зђ¶еПЈзЪДunicodeз†БгАВ
дЄЛи°®жАїзїУдЇЖзЉЦз†БиІДеИЩпЉМе≠ЧжѓНxи°®з§ЇеПѓзФ®зЉЦз†БзЪДдљНгАВ
Unicodeзђ¶еПЈиМГеЫі | UTF-8зЉЦз†БжЦєеЉП
(еНБеЕ≠ињЫеИґ) | пЉИдЇМињЫеИґпЉЙ
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
дЄЛйЭҐпЉМињШжШѓдї•ж±Йе≠ЧвАЬдЄ•вАЭдЄЇдЊЛпЉМжЉФз§Їе¶ВдљХеЃЮзО∞UTF-8зЉЦз†БгАВ
еЈ≤зЯ•вАЬдЄ•вАЭзЪДunicodeжШѓ4E25пЉИ100111000100101пЉЙпЉМж†єжНЃдЄКи°®пЉМеПѓдї•еПСзО∞4E25е§ДеЬ®зђђдЄЙи°МзЪДиМГеЫіеЖЕпЉИ0000 0800-0000 FFFFпЉЙпЉМеЫ†ж≠§вАЬдЄ•вАЭзЪДUTF-8зЉЦз†БйЬАи¶БдЄЙдЄ™е≠ЧиКВпЉМеН≥ж†ЉеЉПжШѓвАЬ1110xxxx 10xxxxxx 10xxxxxxвАЭгАВзДґеРОпЉМдїОвАЬдЄ•вАЭзЪДжЬАеРОдЄАдЄ™дЇМињЫеИґдљНеЉАеІЛпЉМдЊЭжђ°дїОеРОеРСеЙНе°ЂеЕ•ж†ЉеЉПдЄ≠зЪДxпЉМе§ЪеЗЇзЪДдљНи°•0гАВињЩж†Је∞±еЊЧеИ∞дЇЖпЉМвАЬдЄ•вАЭзЪДUTF-8зЉЦз†БжШѓ вАЬ11100100 10111000 10100101вАЭпЉМиљђжНҐжИРеНБеЕ≠ињЫеИґе∞±жШѓE4B8A5гАВ
6. UnicodeдЄОUTF-8дєЛйЧізЪДиљђжНҐ
йАЪињЗдЄКдЄАиКВзЪДдЊЛе≠РпЉМеПѓдї•зЬЛеИ∞вАЬдЄ•вАЭзЪДUnicodeз†БжШѓ4E25пЉМUTF-8зЉЦз†БжШѓE4B8A5пЉМдЄ§иАЕжШѓдЄНдЄАж†ЈзЪДгАВеЃГдїђдєЛйЧізЪДиљђжНҐеПѓдї•йАЪињЗз®ЛеЇПеЃЮзО∞гАВ
еЬ®Windowsеє≥еП∞дЄЛпЉМжЬЙдЄАдЄ™жЬАзЃАеНХзЪДиљђеМЦжЦєж≥ХпЉМе∞±жШѓдљњзФ®еЖЕзљЃзЪДиЃ∞дЇЛжЬђе∞Пз®ЛеЇПNotepad.exeгАВжЙУеЉАжЦЗдїґеРОпЉМзВєеЗївАЬжЦЗдїґвАЭиПЬеНХдЄ≠зЪДвАЬеП¶е≠ШдЄЇвАЭеСљдї§пЉМдЉЪиЈ≥еЗЇдЄАдЄ™еѓєиѓЭж°ЖпЉМеЬ®жЬАеЇХйГ®жЬЙдЄАдЄ™вАЬзЉЦз†БвАЭзЪДдЄЛжЛЙжЭ°гАВ

йЗМйЭҐжЬЙеЫЫдЄ™йАЙй°єпЉЪANSIпЉМUnicodeпЉМUnicode big endian еТМ UTF-8гАВ
1пЉЙANSIжШѓйїШиЃ§зЪДзЉЦз†БжЦєеЉПгАВеѓєдЇОиЛ±жЦЗжЦЗдїґжШѓASCIIзЉЦз†БпЉМеѓєдЇОзЃАдљУдЄ≠жЦЗжЦЗдїґжШѓGB2312зЉЦз†БпЉИеП™йТИеѓєWindowsзЃАдљУдЄ≠жЦЗзЙИпЉМе¶ВжЮЬжШѓзєБдљУдЄ≠жЦЗзЙИдЉЪйЗЗзФ®Big5з†БпЉЙгАВ
2пЉЙUnicodeзЉЦз†БжМЗзЪДжШѓUCS-2зЉЦз†БжЦєеЉПпЉМеН≥зЫіжО•зФ®дЄ§дЄ™е≠ЧиКВе≠ШеЕ•е≠Чзђ¶зЪДUnicodeз†БгАВињЩдЄ™йАЙй°єзФ®зЪДlittle endianж†ЉеЉПгАВ
3пЉЙUnicode big endianзЉЦз†БдЄОдЄКдЄАдЄ™йАЙй°єзЫЄеѓєеЇФгАВжИСеЬ®дЄЛдЄАиКВдЉЪиІ£йЗКlittle endianеТМbig endianзЪДжґµдєЙгАВ
4пЉЙUTF-8зЉЦз†БпЉМдєЯе∞±жШѓдЄКдЄАиКВи∞ИеИ∞зЪДзЉЦз†БжЦєж≥ХгАВ
йАЙжЛ©еЃМвАЭзЉЦз†БжЦєеЉПвАЬеРОпЉМзВєеЗївАЭдњЭе≠ШвАЬжМЙйТЃпЉМжЦЗдїґзЪДзЉЦз†БжЦєеЉПе∞±зЂЛеИїиљђжНҐе•љдЇЖгАВ
7. Little endianеТМBig endian
дЄКдЄАиКВеЈ≤зїПжПРеИ∞пЉМUnicodeз†БеПѓдї•йЗЗзФ®UCS-2ж†ЉеЉПзЫіжО•е≠ШеВ®гАВдї•ж±Йе≠ЧвАЭдЄ•вАЬдЄЇдЊЛпЉМUnicodeз†БжШѓ4E25пЉМйЬАи¶БзФ®дЄ§дЄ™е≠ЧиКВе≠ШеВ®пЉМдЄАдЄ™е≠ЧиКВжШѓ4EпЉМеП¶дЄАдЄ™е≠ЧиКВжШѓ25гАВе≠ШеВ®зЪДжЧґеАЩпЉМ4EеЬ®еЙНпЉМ25еЬ®еРОпЉМе∞±жШѓBig endianжЦєеЉПпЉЫ25еЬ®еЙНпЉМ4EеЬ®еРОпЉМе∞±жШѓLittle endianжЦєеЉПгАВ
ињЩдЄ§дЄ™еП§жА™зЪДеРНзІ∞жЭ•иЗ™иЛ±еЫљдљЬеЃґжЦѓе®Бе§ЂзЙєзЪДгАКж†ЉеИЧдљЫжЄЄиЃ∞гАЛгАВеЬ®иѓ•дє¶дЄ≠пЉМе∞ПдЇЇеЫљйЗМзИЖеПСдЇЖеЖЕжИШпЉМжИШдЇЙиµЈеЫ†жШѓдЇЇдїђдЇЙиЃЇпЉМеРГйЄ°иЫЛжЧґз©ґзЂЯжШѓдїОе§Іе§і(Big- Endian)жХ≤еЉАињШжШѓдїОе∞Пе§і(Little-Endian)жХ≤еЉАгАВдЄЇдЇЖињЩдїґдЇЛжГЕпЉМеЙНеРОзИЖеПСдЇЖеЕ≠жђ°жИШдЇЙпЉМдЄАдЄ™зЪЗеЄЭйАБдЇЖеСљпЉМеП¶дЄАдЄ™зЪЗеЄЭдЄҐдЇЖзОЛдљНгАВ
еЫ†ж≠§пЉМзђђдЄАдЄ™е≠ЧиКВеЬ®еЙНпЉМе∞±жШѓвАЭе§Іе§іжЦєеЉПвАЬпЉИBig endianпЉЙпЉМзђђдЇМдЄ™е≠ЧиКВеЬ®еЙНе∞±жШѓвАЭе∞Пе§іжЦєеЉПвАЬпЉИLittle endianпЉЙгАВ
йВ£дєИеЊИиЗ™зДґзЪДпЉМе∞±дЉЪеЗЇзО∞дЄАдЄ™йЧЃйҐШпЉЪиЃ°зЃЧжЬЇжАОдєИзЯ•йБУжЯРдЄАдЄ™жЦЗдїґеИ∞еЇХйЗЗзФ®еУ™дЄАзІНжЦєеЉПзЉЦз†БпЉЯ
UnicodeиІДиМГдЄ≠еЃЪдєЙпЉМжѓПдЄАдЄ™жЦЗдїґзЪДжЬАеЙНйЭҐеИЖеИЂеК†еЕ•дЄАдЄ™и°®з§ЇзЉЦз†Бй°ЇеЇПзЪДе≠Чзђ¶пЉМињЩдЄ™е≠Чзђ¶зЪДеРНе≠ЧеПЂеБЪвАЭйЫґеЃљеЇ¶йЭЮжНҐи°Мз©Їж†ЉвАЬпЉИZERO WIDTH NO-BREAK SPACEпЉЙпЉМзФ®FEFFи°®з§ЇгАВињЩж≠£е•љжШѓдЄ§дЄ™е≠ЧиКВпЉМиАМдЄФFFжѓФFEе§І1гАВ
е¶ВжЮЬдЄАдЄ™жЦЗжЬђжЦЗдїґзЪДе§ідЄ§дЄ™е≠ЧиКВжШѓFE FFпЉМе∞±и°®з§Їиѓ•жЦЗдїґйЗЗзФ®е§Іе§іжЦєеЉПпЉЫе¶ВжЮЬе§ідЄ§дЄ™е≠ЧиКВжШѓFF FEпЉМе∞±и°®з§Їиѓ•жЦЗдїґйЗЗзФ®е∞Пе§іжЦєеЉПгАВ
8. еЃЮдЊЛ
дЄЛйЭҐпЉМдЄЊдЄАдЄ™еЃЮдЊЛгАВ
жЙУеЉАвАЭиЃ∞дЇЛжЬђвАЬз®ЛеЇПNotepad.exeпЉМжЦ∞еїЇдЄАдЄ™жЦЗжЬђжЦЗдїґпЉМеЖЕеЃєе∞±жШѓдЄАдЄ™вАЭдЄ•вАЬе≠ЧпЉМдЊЭжђ°йЗЗзФ®ANSIпЉМUnicodeпЉМUnicode big endian еТМ UTF-8зЉЦз†БжЦєеЉПдњЭе≠ШгАВ
зДґеРОпЉМзФ®жЦЗжЬђзЉЦиЊСиљѓдїґUltraEditдЄ≠ зЪДвАЭеНБеЕ≠ињЫеИґеКЯиГљвАЬпЉМиІВеѓЯиѓ•жЦЗдїґзЪДеЖЕйГ®зЉЦз†БжЦєеЉПгАВ
1пЉЙANSIпЉЪжЦЗдїґзЪДзЉЦз†Бе∞±жШѓдЄ§дЄ™е≠ЧиКВвАЬD1 CFвАЭпЉМињЩж≠£жШѓвАЬдЄ•вАЭзЪДGB2312зЉЦз†БпЉМињЩдєЯжЪЧз§ЇGB2312жШѓйЗЗзФ®е§Іе§іжЦєеЉПе≠ШеВ®зЪДгАВ
2пЉЙUnicodeпЉЪзЉЦз†БжШѓеЫЫдЄ™е≠ЧиКВвАЬFF FE 25 4EвАЭпЉМеЕґдЄ≠вАЬFF FEвАЭи°®жШОжШѓе∞Пе§іжЦєеЉПе≠ШеВ®пЉМзЬЯж≠£зЪДзЉЦз†БжШѓ4E25гАВ
3пЉЙUnicode big endianпЉЪзЉЦз†БжШѓеЫЫдЄ™е≠ЧиКВвАЬFE FF 4E 25вАЭпЉМеЕґдЄ≠вАЬFE FFвАЭи°®жШОжШѓе§Іе§іжЦєеЉПе≠ШеВ®гАВ
4пЉЙUTF-8пЉЪзЉЦз†БжШѓеЕ≠дЄ™е≠ЧиКВвАЬEF BB BF E4 B8 A5вАЭпЉМеЙНдЄЙдЄ™е≠ЧиКВвАЬEF BB BFвАЭи°®з§ЇињЩжШѓUTF-8зЉЦз†БпЉМеРОдЄЙдЄ™вАЬE4B8A5вАЭе∞±жШѓвАЬдЄ•вАЭзЪДеЕЈдљУзЉЦз†БпЉМеЃГзЪДе≠ШеВ®й°ЇеЇПдЄОзЉЦз†Бй°ЇеЇПжШѓдЄАиЗізЪДгАВ
9. еїґдЉЄйШЕиѓї
* The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets пЉИеЕ≥дЇОе≠Чзђ¶йЫЖзЪДжЬАеЯЇжЬђзЯ•иѓЖпЉЙ
* RFC3629пЉЪUTF- 8, a transformation format of ISO 10646 пЉИе¶ВжЮЬеЃЮзО∞UTF-8зЪДиІДеЃЪпЉЙ


- 2014-05-12 23:27
- жµПиІИ 318
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
иІ£еЖ≥жАЭиЈѓпЉЪињЫи°МBase64еЙНеЕИињЫи°МURLзЉЦз†БпЉМеЬ®ињЫи°МURLзЉЦз†БзЪДжЧґеАЩпЉМж≥®жДПиЃЊзљЃдЄНйЬАи¶БSpaceAsPlusйАЙй°єгАВ javascriptдї£з†БпЉЪ let decodedData = window.atob(JSONStr); let decodedData1 = decodeURIComponent(decodedData)...
зЫЃеЙНе§ІйГ®еИЖзЪДзљСзЂЩпЉМйГљжШѓдљњзФ®зЪДUTF-8зЉЦз†БгАВдЊЛе¶ВеПСйАБдЄАжЃµдЇМињЫеИґеИ∞жЬНеК°еЩ®жЧґпЉМжЬНеК°еЩ®иІДеЃЪиѓ•дЇМињЫеИґеЖЕеЃєзЪДзЉЦз†Б...йЩДдїґжШѓGB18030еМЕеРЂзЪД21004дЄ™ж±Йе≠ЧзЪДGB18030зЉЦз†БгАБUnicodeзЉЦз†БгАБURLзЉЦз†БеѓєзЕІи°®пЉМеПѓзФ®дЇОиІ£еЖ≥дЄ≠жЦЗдє±з†БиљђжНҐжБҐе§НгАВ
жЯРдЇЫйАЪињЗURLжЭ•дЉ†йАБгАБеАЉдЄЇж±Йе≠ЧзЪДеПВжХ∞пЉМеЬ®й°µйЭҐдЄ≠жШЊз§ЇзЪДжШѓдє±з†БпЉМдљЖжШѓеЬ®жЬђеЬ∞еЉАеПСзОѓеҐГжШѓж≠£еЄЄжШЊз§ЇзЪДгАВжОТйЩ§зЪДеЫ†зі†ељУзДґе∞±жШѓжЬНеК°еЩ®зЪДиЃЊзљЃдЄНељУдЇЖпЉМдљЖеЕЈдљУжШѓйВ£дЇЫеОЯеЫ†еСҐпЉЯдЄАиИђжИСдїђжЙАи£ЕзЪДlinuxжЬНеК°еЩ®пЉМжШѓдЄ≠жЦЗзЙИзЪДпЉМжЙАдї•з≥їзїЯзОѓеҐГзЪД...
ињЩжШѓдЄАдЄ™JSжККж±Йе≠ЧиљђжНҐзЉЦз†Бж†ЉеЉПйБњеЕНдє±з†БзЪДз±ї,зЫЄељУдЇОASPжИЦжШѓ.NETдЄ≠зЪДUrlEncodeжЦєж≥Х.дљњзФ®жЦєж≥ХжШѓvar str = UrlEncode("ињЩйЗМжШѓдљ†и¶БиљђжНҐзЪДж±Йе≠Ч");ињЩдЄ™жЦєж≥ХжЬЙдЄ™зЉЇзВє,дЄНжФѓжМБеЕ®иІТж†ЗзВє,жЙАдї•и¶БйЕНеРИдЄЛйЭҐзЪДжЦєж≥ХжККеЕ®иІТиљђжНҐеНКиІТжЙН...
жѓФе¶Вдљ†дЉ†еЕ•ж±Йе≠ЧпЉМжИЦиАЕдЉ†еЕ•вАЭ¬ІвАЭз≠ЙеЕґдїЦзЉЦз†Бж†ЉеЉПзЪДе≠Чзђ¶дЄ≤з≥їзїЯиІ£жЮРеРОзЪДurlдЄЇдє±з†БгАВзїПињЗеЬ®зљСдЄКзЪДжЯ•жЙЊиІЙеЊЧдЄАдЄЛдЄ§зІНжЦєеЉПжѓФиЊГе•љпЉЪ 1.е¶ВжЮЬurlеЬ®еРОеП∞иІ£жЮРзЪДиѓЭйЗЗзФ®HttpUtility.UrlEncode(urlпЉМSystem.Text.Encoding....
дїОAй°µйЭҐйАЪињЗurlдЉ†еПВеИ∞Bй°µйЭҐжЧґпЉМиІ£жЮРurlеПВжХ∞еПѓдї•зФ®дЄЛйЭҐдЄ§зІНжЦєж≥ХпЉЪ жЦєж≥ХдЄАпЉЪж≠£еИЩеИЖжЮРж≥Х дї£з†Бе¶ВдЄЛ: function getQueryString(name) { var reg = new RegExp(вАЬ(^|&)вАЭ + name + вАЬ=([^&]*)(&|$)вАЭ, вАЬiвАЭ); var r = ...
дЄїи¶БдїЛзїНдЇЖescapeзЉЦз†БдЄОunescapeиІ£з†Бж±Йе≠ЧеЗЇзО∞дє±з†БзЪДиІ£еЖ≥жЦєж≥Х,йЬАи¶БзЪДжЬЛеПЛеПѓдї•еПВиАГдЄЛ
иѓ¶зїЖељТзЇ≥дЇЖе§ДзРЖStructsдє±з†БзЪД3зІНжЦєж≥Х дї•еПКURLйЗНеЖЩзЪДж±Йе≠ЧзЉЦз†Бе§ДзРЖзЪДжАїзїУ
VmдЄ≠дЄАдЄ™иґЕйУЊжО•URLйЬАи¶БжЛЉжО•дЄ≠жЦЗдљЬдЄЇGetиѓЈж±ВзЪДеПВжХ∞е¶ВжЮЬзЫіжО•жЛЉжО•пЉМдЉ†еИ∞еРОеП∞ActionзЪДеПВжХ∞еѓєи±°дЄ≠еРОеПЦеЗЇдЉЪжШѓдє±з†БпЉМйЬАи¶БзЉЦз†БеРОеЖНжЛЉжО•еИ∞URLдЄК,жО•дЄЛжЭ•е∞ЖеТМе§ІеЃґеИЖдЇЂдЄАдЄЛиІ£еЖ≥жЦєж≥Х
иІ£еЖ≥urlдЉ†йАТдЄ≠жЦЗдє±з†БйЧЃйҐШпЉМиІ£еЖ≥еРОеП∞жО•жФґеИ∞зЪДж±Йе≠ЧжШѓдє±з†БзЪД
жЬЙдЄАзІНиІ£еЖ≥еКЮж≥Хе∞±жШѓдљњзФ®encodeURIComponentеК†дЄКдњЃжФє Content-Type дЄЇ application/x-www-form-urlencodedвАЭ жЭ•жККжХ∞жНЃзїЯдЄАзЉЦз†БжИР url ж†ЉеЉПпЉМељУзДґпЉМдєЯеПѓдї•жМЗеЃЪзЉЦз†Б,е¶ВпЉЪвАЬapplication/x-www-form-urlencoded;...
зЉЦз†БзЉЦе•љзЪДurlжШѓж≠£з°ЃзЪДпЉМеПѓдЉ†еИ∞еП¶дЄАдЄ™й°µйЭҐ е∞±дЉЪеЗЇйФЩпЉМеЬ®еЬ∞еЭАж†Пе∞±еЈ≤зїПдє±з†БдЇЖ 1.иЃЊзљЃweb.configжЦЗдїґ дї£з†Бе¶ВдЄЛ: <system> вАЭgb2312вА≥ responseEncoding=вАЭgb2312вА≥ culture=вАЭzh-CNвАЭ fileEncoding=вАЭgb2312вА≥> ...
пЉИ1пЉЙйЧЃйҐШеЗЇжЭ•дЇЖпЉМељУвАЬжЧ•еЇ¶жМЗж†ЗвАЭеТМвАЬжЬИеЇ¶жМЗж†ЗвАЭеИЗжНҐзЪДжЧґеАЩпЉМзФ±дЇОжИСдЉ†йАТзЪДеПВжХ∞дЄЇж±Йе≠ЧпЉМеЬ®еРОеП∞иОЈеПЦдЄЇдє±з†БпЉМ дЇОжШѓињЫи°МзїЩеПВжХ∞ињЫи°МencodeзЉЦз†БпЉМеРОеП∞UrlDecodeиІ£з†БпЉМйГБйЧЈзЪДеПСзО∞ињШжШѓдє±з†БгАВ зДґеРОдїФзїЖеѓєзЕІй°µйЭҐзЪДзЉЦз†БеПСзО∞пЉМи¶Б...
еИ©зФ®JavaScriptйАЪињЗURLжЦєеЉПеРСеРОеП∞дї£з†БдЉ†еАЉжШѓдЄАзІНзїПеЄЄзФ®еИ∞зЪДжЙЛжЃµпЉМдљЖеЬ®дЉ†йАТж±Йе≠ЧжЧґзїПеЄЄдЉЪеЗЇзО∞е≠Чзђ¶дЄНеЕ®жИЦеПШжИРдє±з†БзЪДйЧЃйҐШпЉМеЕґеОЯеЫ†жШѓзФ±дЇОеЃҐжИЈзЂѓIEжµПиІИеЩ®зЪДзЉЦз†БжЦєеЉПдЄЇGB2312пЉИзЃАдљУдЄ≠жЦЗзЙИWINDOWSзЪДйїШиЃ§иЃЊзљЃпЉЙпЉМиАМеРОеП∞зЪДC#...
urlдЉ†йАТж±Йе≠ЧзЪДиІ£еЖ≥жЦєж≥Х encodeURIComponent encodeURI зЪДеМЇеИЂ
еЬ®зљСзЂЩеЉАеПСињЗз®ЛдЄ≠,дљњзФ®ж±Йе≠ЧдЉ†иЊУдЉЪеѓЉиЗіжЬЙжЧґURLдЉЪеЗЇзО∞дє±з†БзЪДйЧЃйҐШ,еПѓйАЪињЗurlencodeеѓєдЄ≠жЦЗињЫи°МзЉЦз†БпЉМзДґеРОеЖНиІ£з†БпЉМйБњеЕНеЗЇзО∞дє±з†БпЉМж≠§еЗљжХ∞еК†еѓЖзЪДе≠Чзђ¶дЄ≤еПѓйАЪињЗphpзЪДurldecodeињЫи°МиІ£з†Б
дњЃжФєжЙ©е±ХзХМйЭҐжФѓжМБеЇУдЄАпЉМз¶Бж≠ҐйАПжШОж†Зз≠ЊеЬ®зИґз™ЧеП£еИЈжЦ∞жЧґиЗ™еК®еИЈжЦ∞пЉМдї•иІ£еЖ≥еЕґеѓЉиЗіз™ЧеП£еИЈжЦ∞зЉУеЖ≤зЪДйЧЃйҐШгАВ 8. жФєињЫеЇФзФ®жО•еП£жФѓжМБеЇУдЄ≠вАЬиЃЊзљЃе±ПеєХеИЖиЊ®зОЗвАЭеСљдї§гАВ 9. дњЃжФєе§ЦйГ®жХ∞жНЃеЇУеЬ®вАЬи°®дЄ≠иЃ∞ељХжХ∞дЄЇйЫґвАЭжЧґеПѓиГљеѓЉиЗіз®ЛеЇПеі©жЇГзЪД...
иЃ©дљ†зЯ≠жЧґйЧіеЖЕзФ±дЄАеРНиПЬйЄЯеИ∞йЂШжЙЛзїЭеѓєж≤°йЧЃйҐШ! зФ±дЇОжЭГйЩРжЬЙйЩР,еИЖ3йГ®дїљдЄЛиљљ PHPз®ЛеЇПеЉАеПСиМГдЊЛеЃЭеЕЄ еЖЕеЃєжПРи¶Б гАКPHPз®ЛеЇПеЉАеПСиМГдЊЛеЃЭеЕЄгАЛеЕ®йЭҐдїЛзїНдЇЖеЇФзФ®PHPињЫи°МзљСзЂЩеЉАеПСзЪДеРДзІНжКАжЬѓеТМжКАеЈІгАВгАКPHPз®ЛеЇПеЉАеПСиМГдЊЛеЃЭеЕЄгАЛеИЖдЄЇ20зЂ†...